

InfraNodus can be used to quickly understand the content of any book, getting an overview of the main ideas, and the main topics.
Here is a short video tutorial that presents this workflow and a step-by-step guide below.
Step 1: Find a Book that You'd Like to Analyze
You would need the book as a .PDF or a .TXT file. If you have it on a your personal reading device, you could try to export it. Otherwise, you could use public resources like 1lib.at to download the book you like.
Step 2: Add the Book to InfraNodus
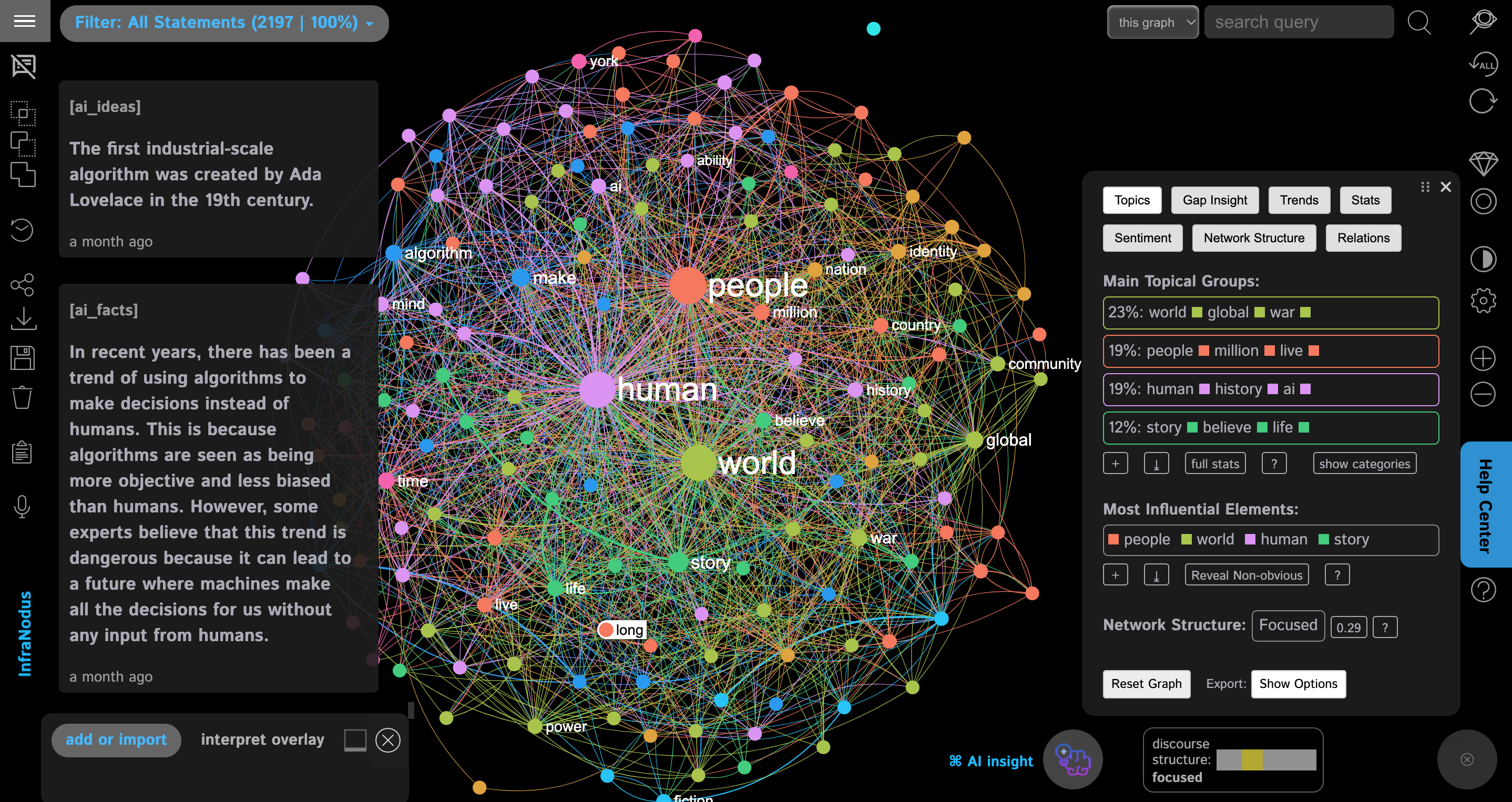
Go to https://infranodus.com/apps and choose the PDF or the Book Import App. Add the file and click "Save". After some seconds you will have the book visualized as a graph. In this case, it's Yuval Harari's 3 books "Homo Sapiens", "Homo Deus", and "21 Lessons for the 21st Century" at once:
If you would like to learn more about the algorithm, please, refer to https://infranodus.com/#about where we explain it in detail (with a reference to our whitepaper).
Step 3: Discover the Main Concepts and Topics
The text network is an overview of the content. The bigger nodes are the concepts that are frequently used in the books. The color indicates the topical clusters or the groups of concepts that are frequently used together.
In the example above, we quickly understand that Harari is talking about "human" and "people" in the "world" (3 top concepts), another important concept is "story".
Then we also have the top topical clusters:
"world global war"
"people million live"
"human history ai"
"story believe life"
We can interpret the meaning of these topics ourselves (e.g. by rephrasing them: "He's talking about the war, the life of people, the AI and its role in human history, and human stories and beliefs and how they affect our life") We can also use the AI to generate the taxonomy for these topics:
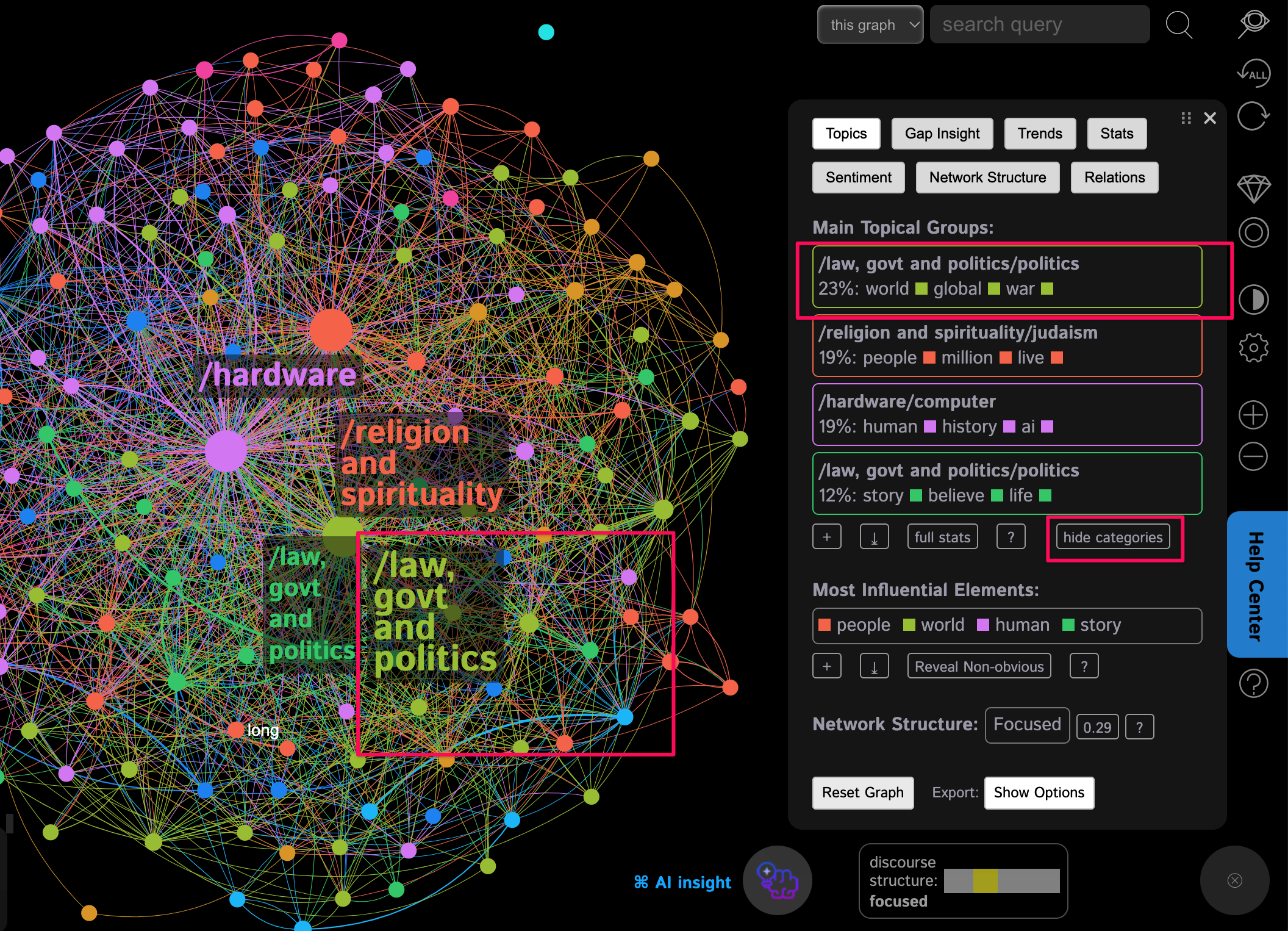
We now understand the general content of the book (politics, spirituality, technology) and can now explore the content a little bit deeper.
Step 4: Explore the Relations between the Concepts — Non-Linear Reading
Now we can choose the words / nodes in the graph that you're interested in and see in which context they're used.
In order to do that, click the words that you're interested in (e.g. "algorithm" and "mind") and you will see in which context those terms are used in the book.
For example:
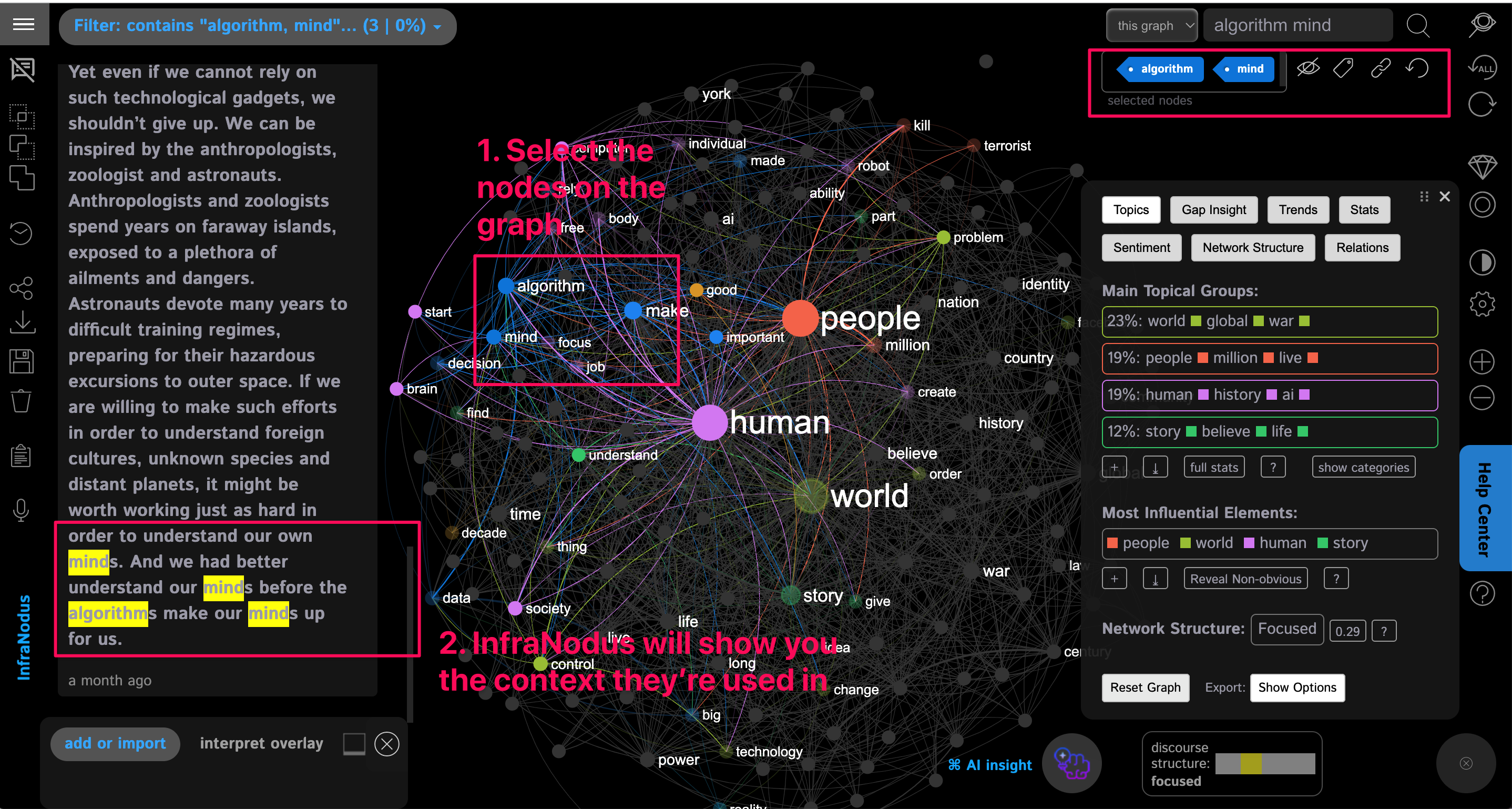
We can then select several other word combinations to explore the content in this non-linear way.
Note, that if you click on Analytics > Relations panel you will also see which other words are connected to the concepts you selected. This is also shown on the graph, but the "Relations" panel shows the relative importance of each connection, so you can use it to compare groups of concepts:
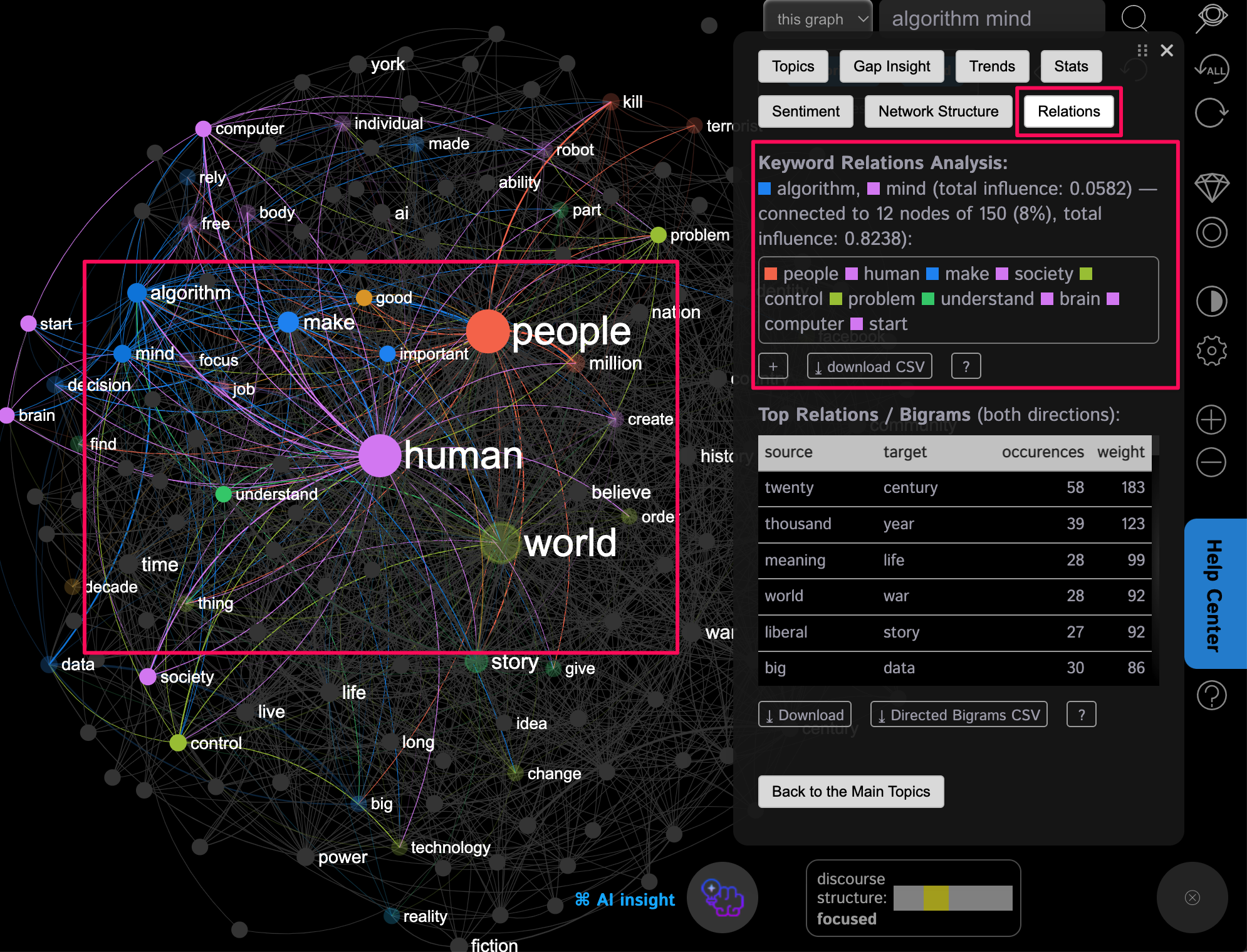
Step 5: Find the Structural Gaps
The structure of the network allows you to see which parts of the discourse could be connected but are not connected yet. These are the structural gaps in the text network. You can use them to generate new ideas that bridge those gaps and, thus, bring new and interesting ideas into the discourse. Read more about it on Identifying Structural Gaps in a Discourse
Step 6: Discover the Nuance, Explore the Periphery
After you perform the analysis with the initial network structure, you can start removing the layers of the most influential nodes to see what's hiding behind them.
Select the most popular nodes, such as "human", "people", "world" and hide them from the graph. The network metrics will be recalculated and the new topical clusters will emerge. These clusters will show you the less obvious parts of the discourse that were hidden behind the main topics.
Read more about this graph exploration workflow on Revealing the Non-Obvious: Graph Exploration Workflow
Comments
0 comments
Please sign in to leave a comment.