

InfraNodus has a built-in text network structure analysis system that measures how biased or diverse the discourse structure is. This approach is used for a conversational chat bot built on the basis of OpenAI's GPT-3, which is designed to steer the structure of a conversation towards a diversified state. The chatbot uses the main insights we obtain from a text network to generate a response (topics, structure, most influential terms), which are then integrated into the GPT3 prompt.
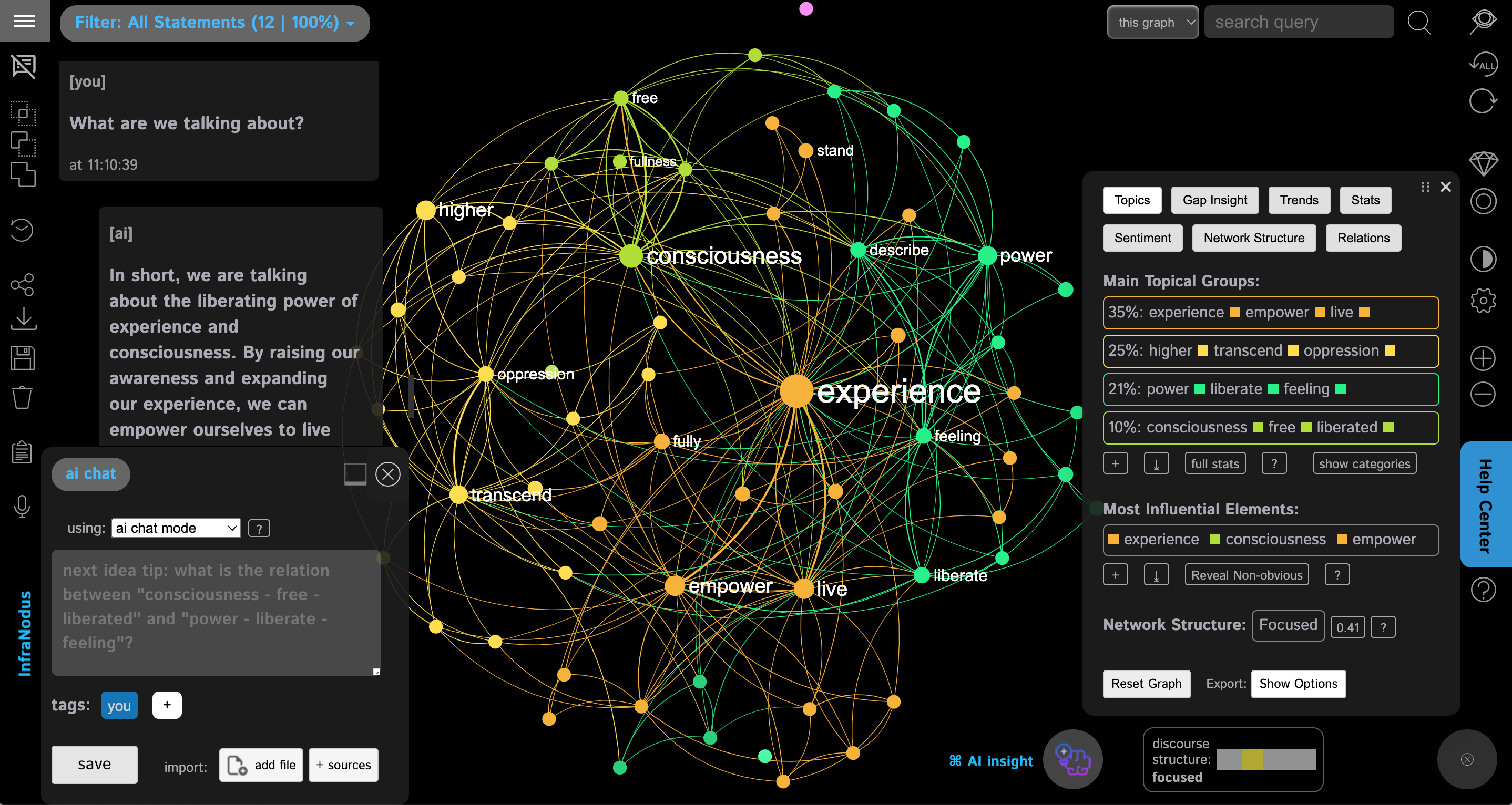
The difference from the standard chatbots is that InfraNodus' bot will always try to make the conversation more "interesting" by steering it towards the less represented topics, while also taking into account the network structure of the discourse and the topics within.
In that way, it follows the "ecological variability" model for discourse development where the chatbot will aim to link your ideas if they are too dispersed, or to diversify them if they are too strongly connected:
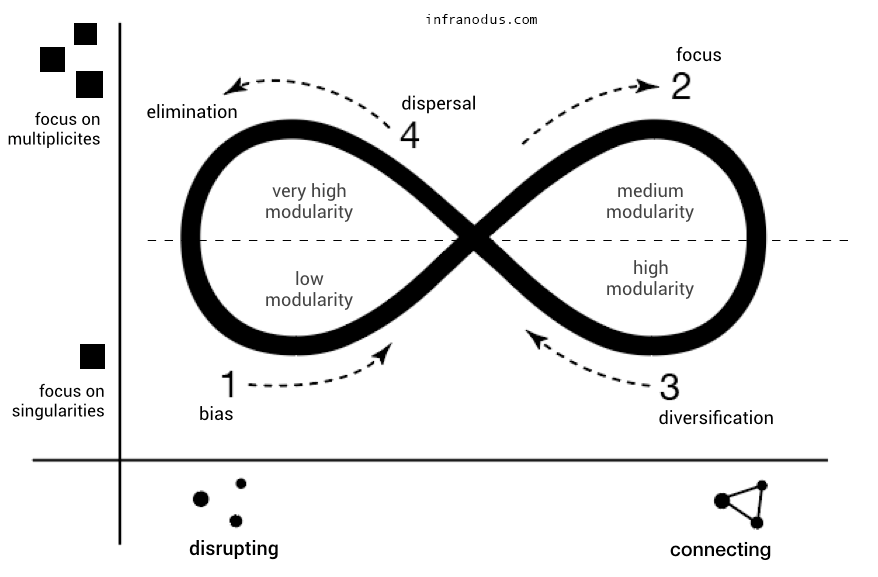
The image above shows the schema that is used in this approach. We start from a singular idea (stage 1), where we have low modularity (no distinct clusters of concepts).
We then start adding more ideas and creating connections between them. At some point, we reach stage 2, where our ideas are sufficiently connected and also we have several of them (max multiplicity, max connections, medium modularity).
This is a plateau, so we need to change strategy to develop the idea further. We start focusing on singularities again (zooming into the specifics), while maintaining the connectivity (diversification — from stage 2 to stage 3).
Once we diversified the discourse, we need some new ideas to flow in, so we disrupt the structure and focus on multiplicities again (stage 4).
This allows us to bring new ideas in or to develop a periphery. We can then focus on singularities and start connecting ideas again (stage 1).
How do We Measure a Text's Network Structure
The network structure measure in InfraNodus based on the modularity measure (the presence of topical clusters) in combination with the distribution of the most influential nodes across the topical clusters. As a result, we can see whether a text's structure is highly interconnected, focusing on one or two concepts, or whether it's diverse and spans over a range of distinct topics.
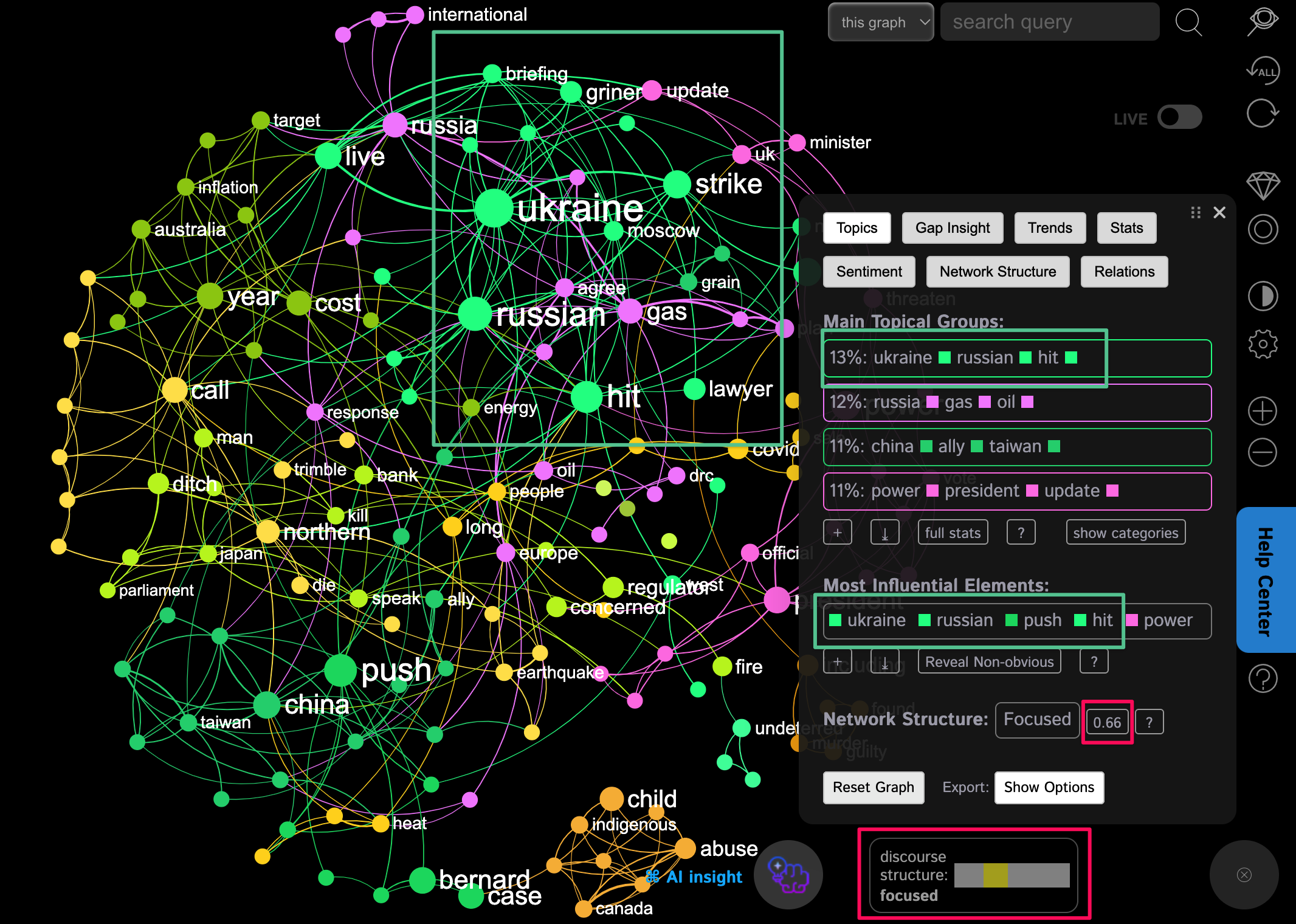
For example, in the graph above, which is a visualization of the news of the day (as of 27/07/2022), we have a diverse network structure. The modularity measure shown inside the pink square is 0.66, which is more than 0.4, indicating a highly pronounced topical structure.
However, the structure is still ranked as "Focused" because 4 out of 5 of the most influential nodes are concentrated in one topical cluster, which means there is a bias towards one of the topics (Russia - Ukraine conflict). So that's why we rank the structure not as "Diversified" but as "Focused" in this case.
Alternatively, if we look at the Twitter discourse graph of the day, we will see that the discourse structure is ranked as Diversified, because the modularity measure is high and the most influential nodes are equally distributed between the different topical clusters:
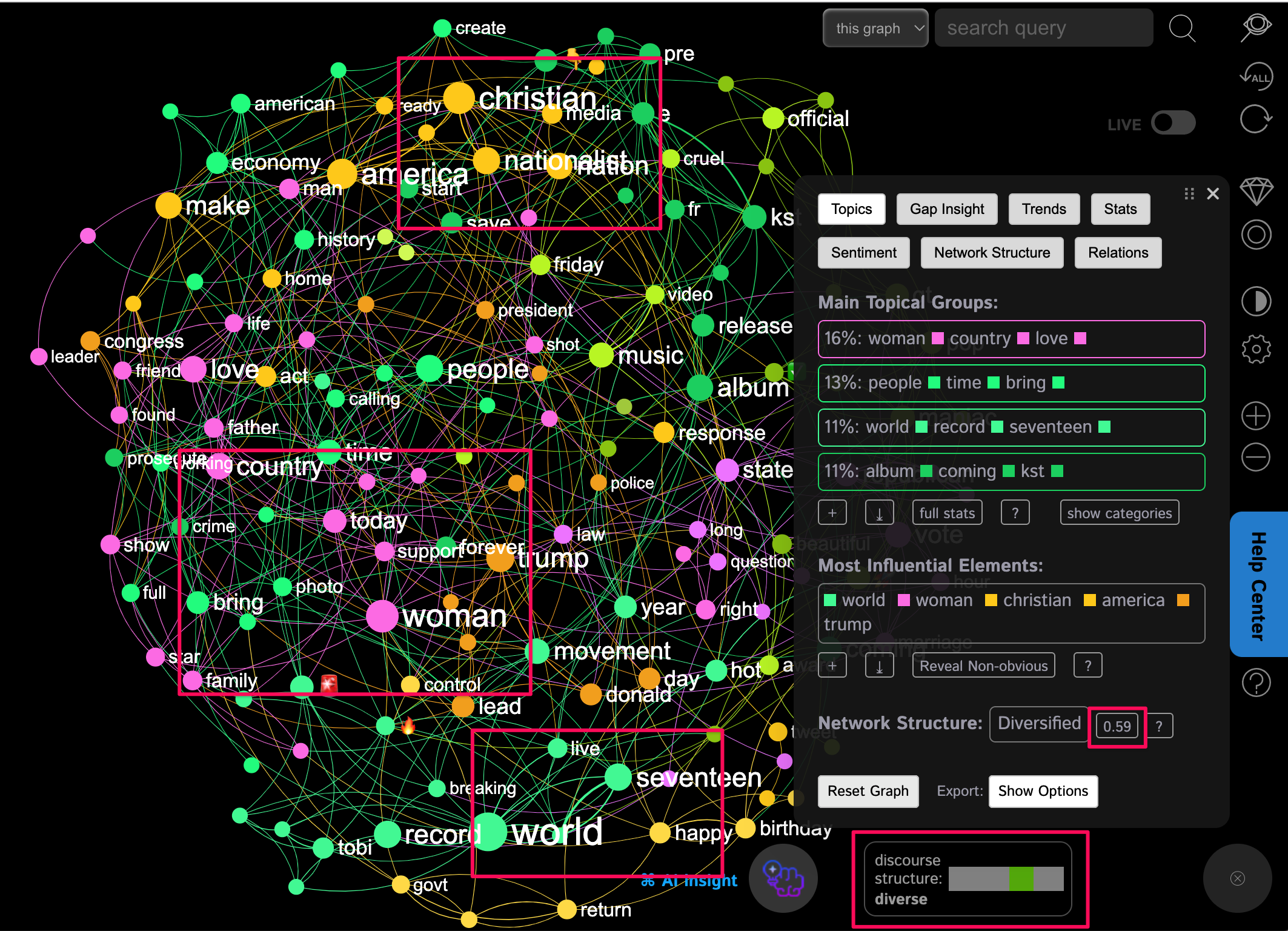
In the same way, when we steer a conversation using the chatbot, we take account of what's happening in the network structure. If it's too "connected" or focused, like in the first case, the chatbot will take into account not only your immediate prompt, but also the smaller, less represented parts of the discourse. Which makes it generate an answer that develops a certain peripheral topic and thus contributes to the discourse's diversity. At the same time, if the discourse is too diversified, the chatbot will focus on the top topical clusters and the top nodes to generate an idea that would link them together, strengthening the most important parts of the discourse and creating more links between them.
Comments
0 comments
Please sign in to leave a comment.