

InfraNodus can be used to classify texts and to identify the topics that they belong to. This can be helpful for summarization, overview, text classification, or developing a taxonomy for a corpus of documents.
The topical clusters are shown in the Analytics panel. These are identified based on the words that tend to appear together in the text. If you would like to generate a classification for the topical clusters, click Show Categories and you will see the categories that are derived from each topical cluster using ML algorithms:
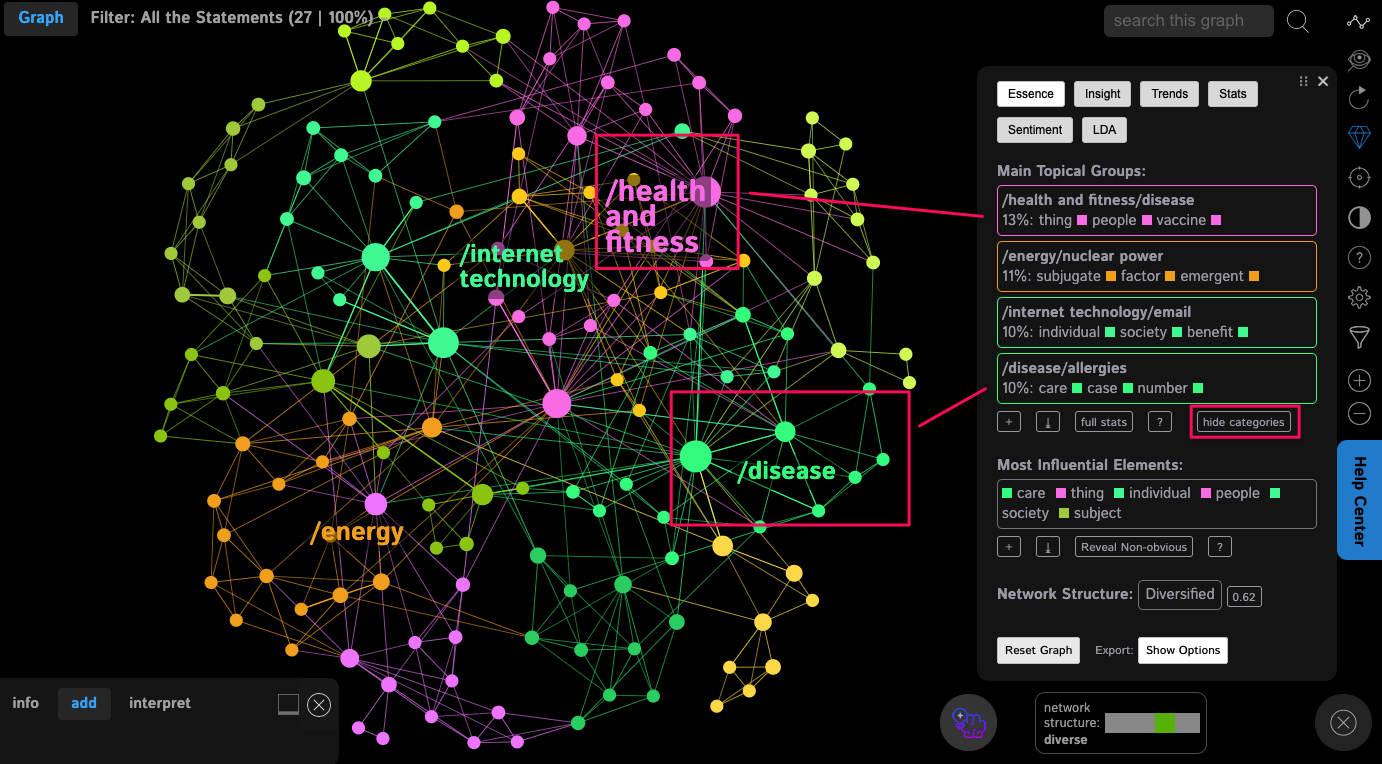
You can use this data to
- get a better overview of the topics contained within a text
- generate a list of categories / tags for a text
- tag every statement within a text with a category that it belongs to
- classification of data in a text corpus
Here is how this approach works, step by step:
1. Topical Clusters
InfraNodus can analyze any text and identify the main topics using text network analysis. The topics are identified based on keywords' co-occurrence: the more often certain words tend to occur together in a particular text, the more likely they are to form a topical cluster. The topical clusters are shown with a distinct color on the graph and in the analytics panel:
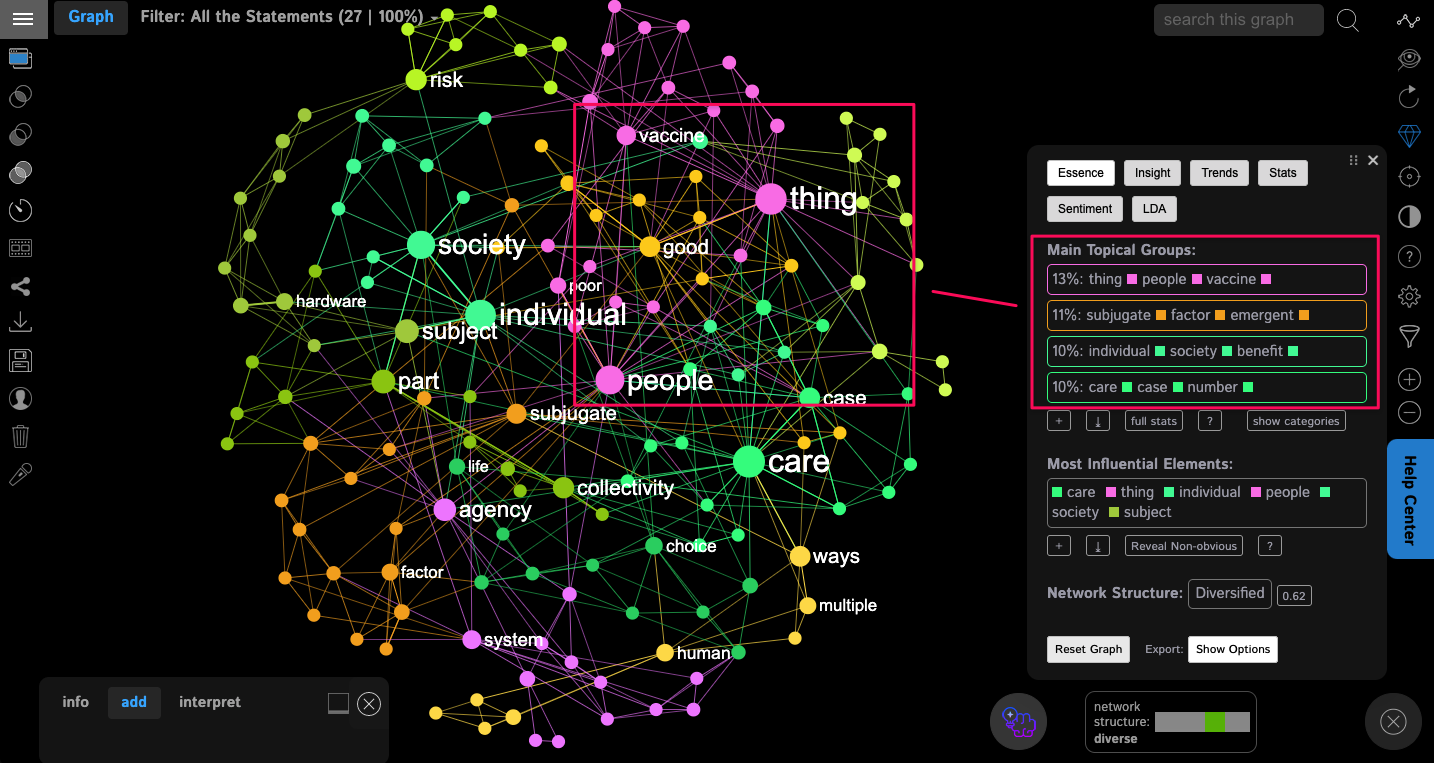
You can identify what the topic is about by looking at all the words in every topical cluster. For instance, in the example above, we see that the topic #3 is about individuals, society, and benefit — so, probably, something about social relations.
2. Text Classification using Topic Categories
You can use the content of the topical clusters to better understand what each topic is about. Alternatively, you can click the "Show Categories" button and the classification will be automatically generated for you.
Our algorithm will send all the words that belong to a topical cluster to the IBM Watson's AI that will generate a classification for each topical cluster and show it back in the graph:
3. Tagging Statements and Data Export
Once you generate the topical clusters and the categories for each cluster, you can export this data.
Also, you may find it interesting that every statement in a text is tagged with the topic that it belongs to. This can be useful for classifying the statements inside a text into different topics — for instance, for Tweets, customer support chats, your own ideas, reviews, notes, etc.

As a result, you will get a CSV file where the first column are the text statements, and the other columns will contain the topical clusters and categories they belong to:
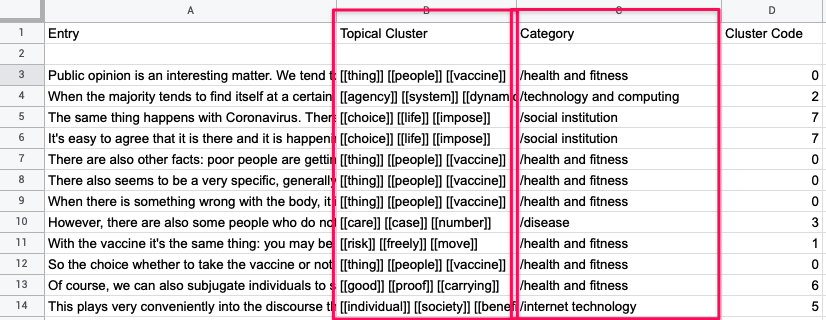
This can be very useful if you want to split people into groups based on the feedback that they provide and on their affinity to a certain topic. Or to discover the categories present within a text and better understand how a certain discourse traverses through the topics.
Comments
0 comments
Please sign in to leave a comment.