

A network is a representation of a process where relatively stable states are represented as the nodes and their interactions are represented as the edges. Once we construct a network, we can apply various methodologies (such as graph theory) to better understand the underlying processes and the nature of those interactions.
A network's type will define how resilient or adaptive it is, how well information can be propagated through it, how susceptible it may be to an attack.
We provide insight into the network's type in InfraNodus text network analysis tool to indicate how easily information and meaning can propagate through a discourse.

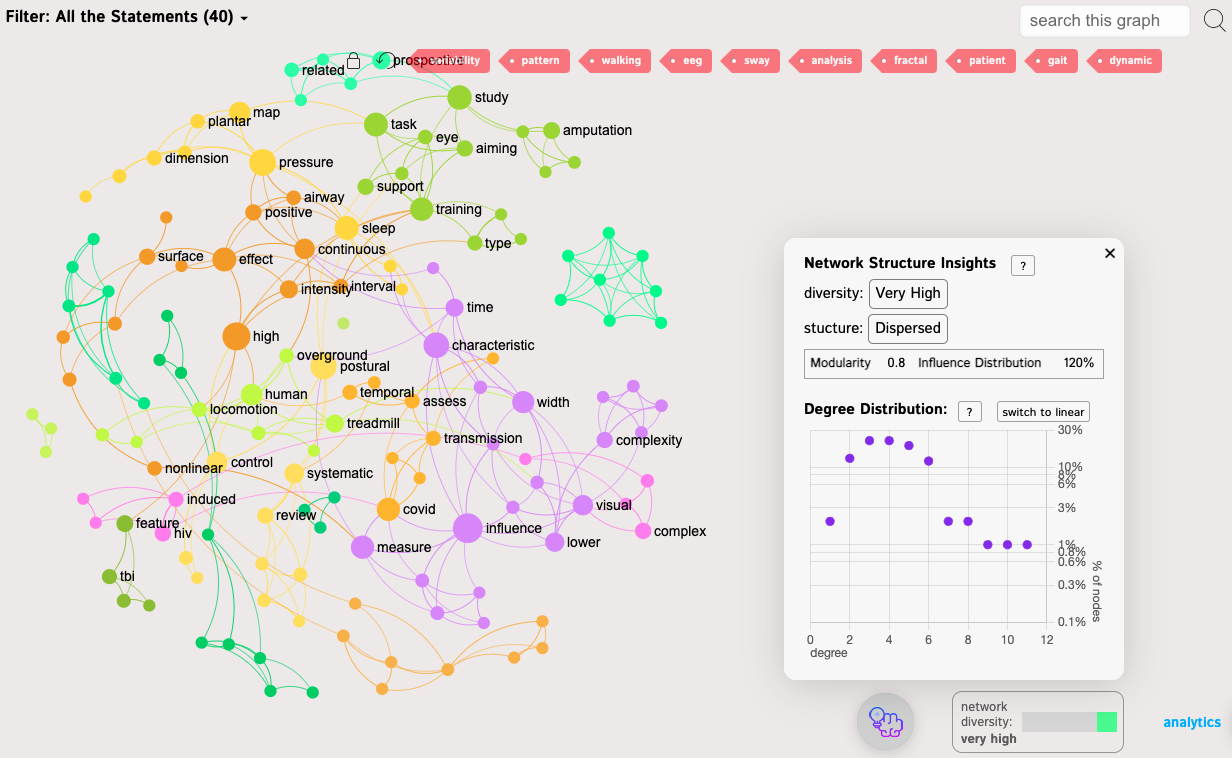
One of the best indicators of the network's structure is the presence of the hubs or the hyper-connected nodes. For instance, on the network above, which represents the scientific discourse around the topic of "fractal dynamics" (extracted using InfraNodus from the scientific publications), we have a few nodes ("dynamic", "fractal", "gait", "patient") which have significantly more connections than most of the other nodes in this network. This is an indicator of a so-called "scale-free" network and those networks are known to be resilient against random attacks while also enabling the propagation of information through it. In the context of text network analysis, this means that the discourse has a certain degree of plurality (topical clusters forming around the distinct hubs) and yet, it is also interconnected (so we can reach one part of the discourse from another).
Scale-Free Networks, Power Law Distribution, and Long Tail
We can, of course, see a network's structure visually, but if we want a more objective measure, we can use the network degree distribution chart (available in InfraNodus). A scale-free network will have a degree distribution that follows a Power law and/or has a long tail — that is, there are a few, but a significant number of nodes that have many connections (hubs), while most nodes in the network have significantly fewer connections.
To illustrate what that means, we can use the degree distribution chart from InfraNodus. On the X-axis of this chart, we have the number of degrees, on the Y-axis of this chart, we have the number of the occurrences:
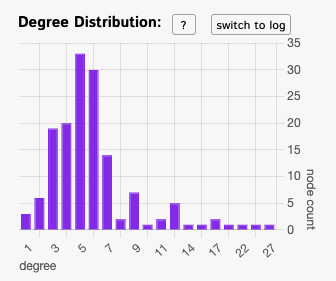
As you can see, this distribution has a long tail and there are a few, but a significant number of nodes that have a much higher degree than the average (3, in this case).
This can be seen slightly better on a logarithmic scale that relates the degree of the nodes to the probability of their occurrence (% of nodes):

As you can see, the majority of nodes (75%) have a degree below 7. While about 25% of nodes have >= 7 connections. This is related to the so-called Pareto principle: where 20% of causes are responsible for 80% of the outcomes, which is a specific case of a Power law.
Mathematically, the power law is expressed using an equation p(d) ~ d(-) or p(d) ~ (1/d)where the fraction p(d) (%) of the nodes with a certain number of connections will decrease at power rate a to the number d of the connections (hence, the power law). Usually, this parameter (the power) will be > 1 for the network to satisfy the power law distribution. A network, whose distribution follows a power law is called scale-free.
 ) or p(d) ~ (1/d)
) or p(d) ~ (1/d)A special case of a scale-free network is a small-world network in which the hubs have most of the connections but are also connected to one another. This is why they are called small-world: it's easy to reach from one part of this network to another. In the case of text networks, small-world networks indicate the kinds of discourses that have a certain level of plurality and where all the distinct topics are integrated on the global level.
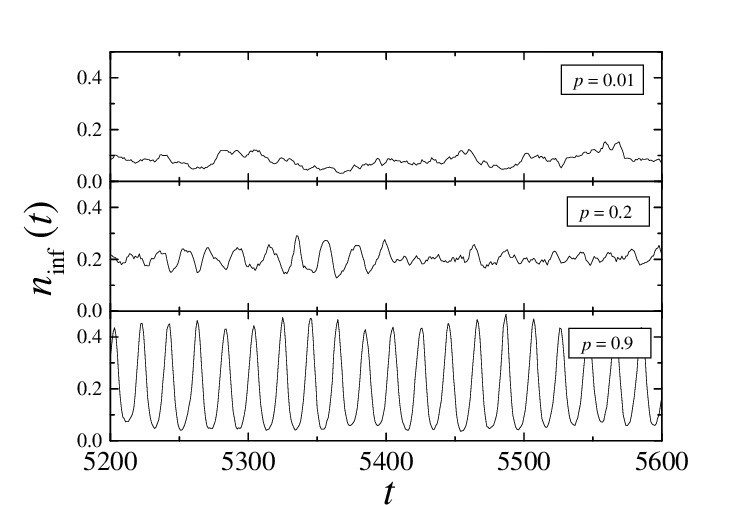
Both scale-free and small-world networks are known to be resilient against random attacks and when propagation occurs, it will probably reach all the different parts of the network in a shorter period of time (see the chart below with the probability of connection between any two random nodes is p = 0.2).
How to Identify a Power Law Distribution: Kolmogorov-Smirnov Test
In InfraNodus, you can analyze the graph degree distribution graph to better understand whether it fits the power law.
You can also use the Kolmogorov-Smirnov test results shown under the graph, which indicate how well the network's degree distribution fits an idealized power law distribution (we check against ^1, ^1.5, and ^2. If the value d of the KS-test is lower than the critical value cr, the two distributions may be considered to be similar, indicating a presence of the power law.
The higher is the power shown, the stronger is the inequality between the nodes. If you want an equalized text, where there are distinct topics that are also integrated on the global level, it may be interesting to aim for the power ^1 (not more).
Normalized Degree Distribution
If the number of connections between the less connected nodes increrase, or if we remove the hubs, the same number of connections between the nodes will equalize. Such a network will start losing its scale-free properties and its degree distribution will not follow the power law and will look more like the normal bell-curve distribution. Such network is closer to random (because we could generate it automatically if we randomly linked the nodes to each other without giving the preference to the hubs).
The networks with a decreased scale-free property will be less resilient against random attacks, while propagation in such networks occurs in faster and more intense cycles.
At the same time, power may be more equally distributed in such a network. So in the case of a discourse network, this may indicate texts that are focused on one topic only (e.g. highly ideological, focused messages) or the texts that do not give a preference to the most commonly used words (e.g. poetry)
Such a network can be generated from the small-world one, if we start connecting the nodes randomly to one another (see the chart with a probability of connection p = 0.9 below).
For example, if we take the network above and delete the most connected nodes from it, we will see that the distribution will now not have a long tail, indicating that it does not follow the Power-law any longer.
How to Interpret the Degree Distribution?
In the context of text networks, knowing the network's type can help us understand the dynamics of how the narrative unfolds. For instance, if we are looking at two discourse network (A and B), where A has a stronger Power-law distribution than B, we know that the narrative in B will be propagated in waves, passing through the most influential nodes. While for the scale-free network B, it will be much more focused on the different topics, going in-depth on each of them, then switching the others.
We will also know that the discourse A, with a stronger power-law distribution, may be more resilient against a randomized infiltration, but is very susceptible to a targeted infiltration attack.
...
All illustrations are made using InfraNodus network analysis tool. You can also see all the metrics we talked about above in InfraNodus Analytics > Network Structure panel.
Comments
0 comments
Please sign in to leave a comment.