

InfraNodus automatically identifies the topical clusters in your graph.
Each topical cluster is based on the Louvain community detection algorithm, which is widely used in network science. The nodes that are more densely connected together (i.e. have a tendency to co-occur often together) will belong to the same "community" or, as we call it, Topical Cluster.
InfraNodus will also classify each statement of your original text (raw data) with the topical clusters that it belongs to. So you can use text network analysis for classification of your original text statements into groups (e.g. customer reviews, tweets, or intention statements). You can then use this data for further analysis or as additional features for machine-learning applications in order to improve your models.
Topical Clusters
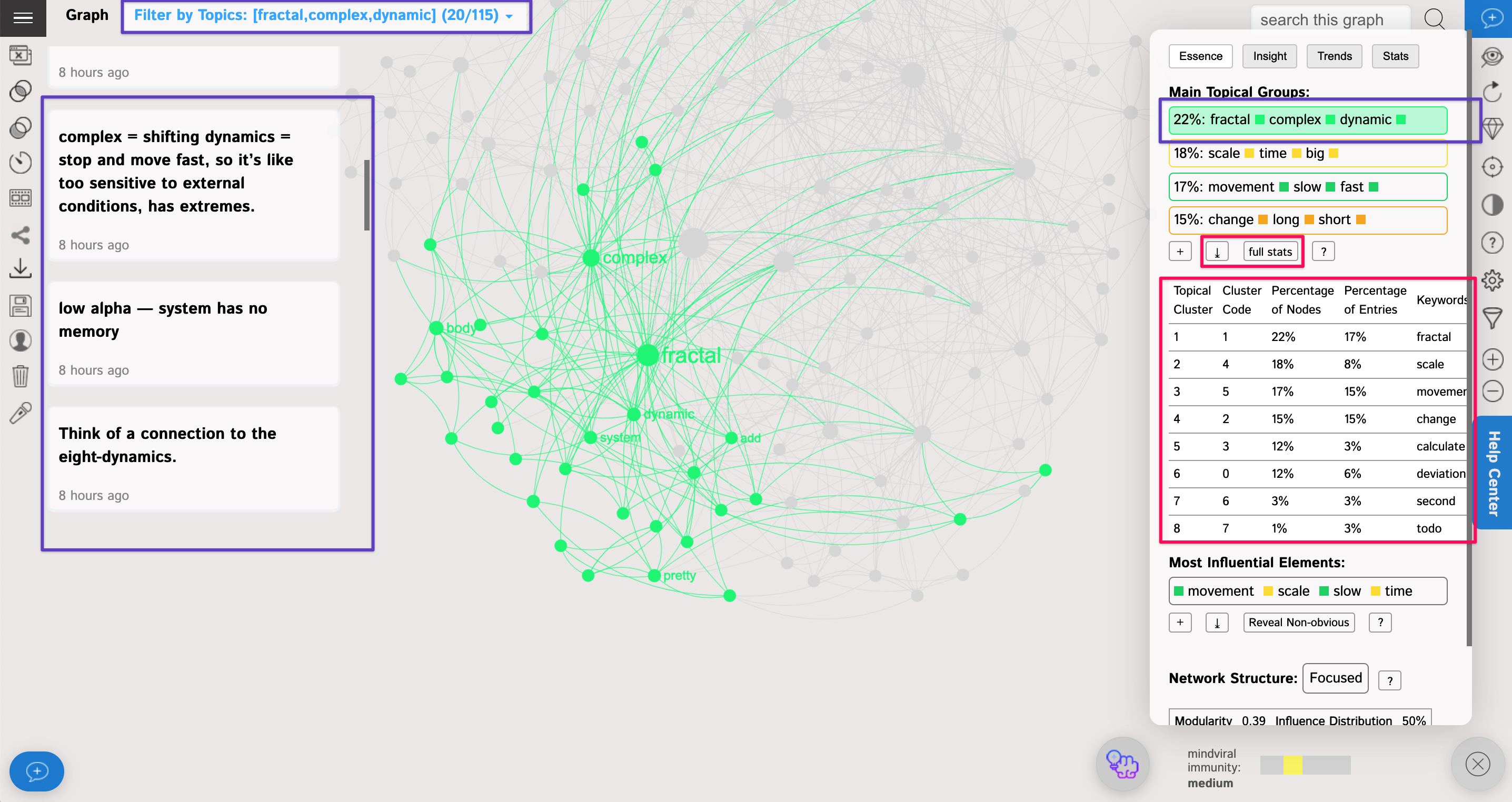
Using the topical cluster dialog in the Analytics panel you can see:
1) The percentage of nodes belonging to each cluster
2) The top 3 keywords that belong to each of them
If you click on the "full stats" button, you'll be able to see the full list of keywords in each topical cluster, as well as:
1) The code numbe of the topical cluster ("Cluster Code")
2) The pecentage of nodes in each cluster
3) The percentage of entries in each cluster
4) All the keywords belonging to each cluster
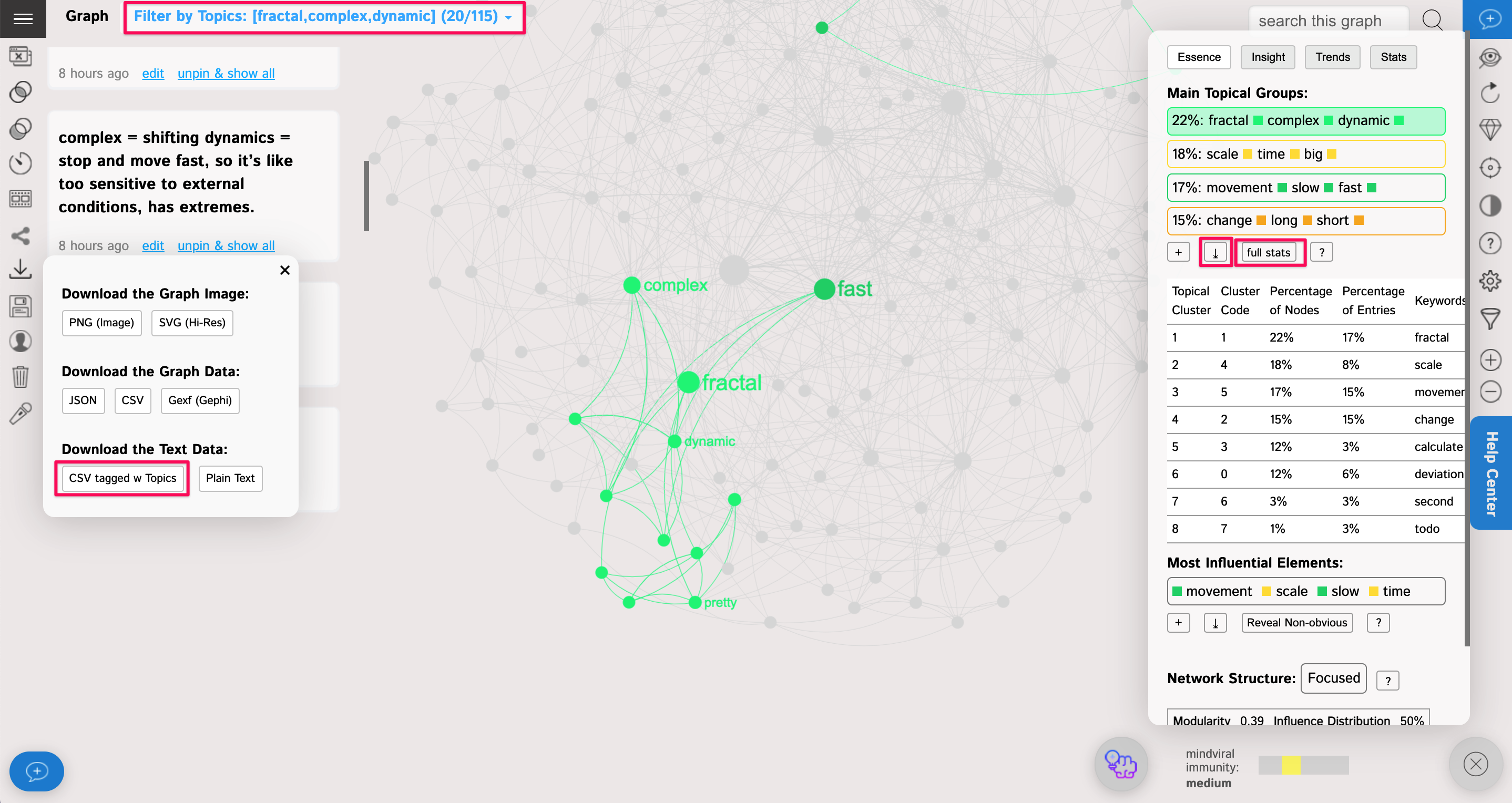
To export this data as a CSV / spreadsheet file, click the "download" button next to the "full stats" button.
If you click on a specific topical cluster, you will see the statements that belong to it (classified to belong to this topical cluster), so you can quickly get to the parts of your data that are relevant for your analysis.
Classification of Text Statements
Once the topical clusers are calculated, each of your original statements is classified to the topical cluster that it belongs to. You can get access to this information visually if you click on the topical cluster: you will then see the statements that belong to it, and also the number of the statements (in relation to the total) that are in this topical cluster.
You can also export this data if you click on the Export > CSV tagged w Topics button. You will then download a spreadsheet (csv file) with all the statements that are classified by the topical clusters they belong to. An additional column called "Cluster Code" is added, in case you need to connect this table to the one above.
You can then use this data to classify your original statements into groups.
For example, if your original data are the brief descriptions of a conference presentation from every person, you could use this information to split the original group into subgroups by the topics that they seem to be most interested in. You could also classify research papers, your own ideas, or tweets based on the same approach.
The classification that you obtain this way can be used for machine learning models. For instance, you could generate a training set where the labels are the topical clusters and see if your model can generate interesting results for the short snippets of text, which is not always an easy task.
Comments
0 comments
Please sign in to leave a comment.