

Text network analysis can be used to analyze your spreadsheet / CSV / Excel data.
It could be useful for analyzing open survey answers — in that case you'd need just one column of data and InfraNodus will process every column separately.
It could also be useful if you wanted to find patterns in relations. In that case you could import two columns: so that one column is the "source" in the graph and the other one is the "target".
There are also more advanced import features available in InfraNodus letting you choose one of the columns to be used for categorization. So, for instance, if you have negative / positive sentiment in the Sentiment column, you could choose that to be the criteria to separate the graphs and in that case you'd build two graphs: one with only the negative sentiment and one with only the positive and be able to compare them.
Step-by-Step CSV / Excel Import:
1. Prepare your data: InfraNodus can accept CSV files or you can also copy and paste your data from Excel.
2. Go to InfraNodus apps and open the Import File app (CSV).
Alternatively, you can simply copy your data from an Excel spreadsheet and insert it as a text into the standard Text processing app of InfraNodus. The system will automatically treat the data in the same row as connected. Every column will be a new statement, so there won't be connections between the columns.

3. Choose the CSV file, upload it, you will see a preview. In our case it's the names of the conference papers presented at The Web Conference 2019:
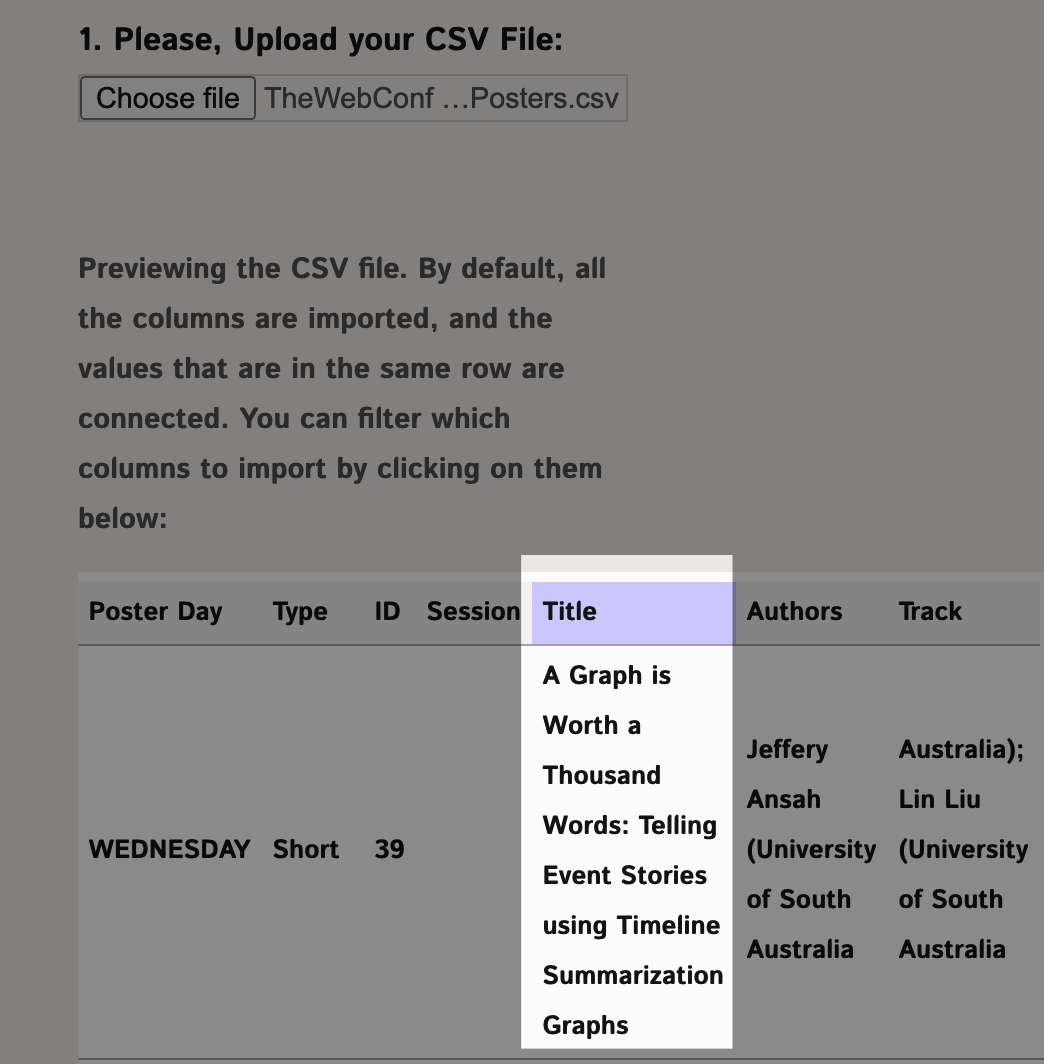
4. You can then choose the columns from which you will import the data. In this example, we choose one column named "Title" with the titles of the conference papers, because that's what we want to analyze.
If you don't choose any columns, all the data in the file will be imported and every row will be treated as a sequence of text to connect. If you choose two columns, then the data in each row of these columns will be connected. This could be useful if you are interested in the relations between the columns, e.g. Origin / Destination for transportation networks or airline tickets database.
5. Additionally, you can also choose which columns will be used for categorizing and tagging data. For instance, if you want to be able to filter the insight for Male and Female responses separately, you would choose the Gender column.
In our case we use the Poster Day and the Type of the presentation, which will be added as the two different types of filters for the graphs that we're going to generate.
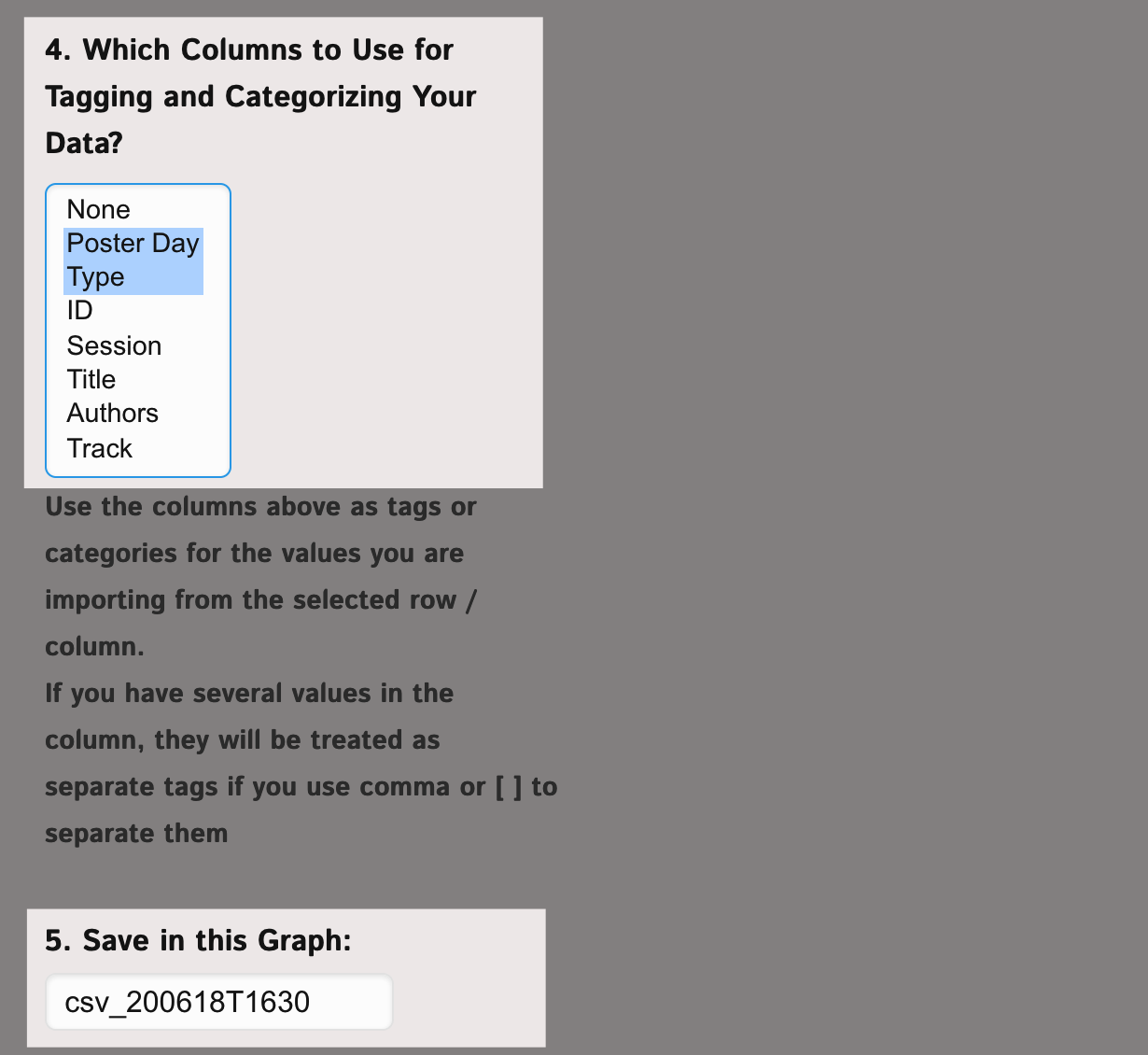
You can also choose the name of the graph where you want your data to be saved (by default: csv_yymmddthhmm
6. Once you have the file visualized, you will be able to see the statistics for the main topics that are present inside and the relations between them. You will also see what's missing in the graph: which clusters could be connected but are not yet, helping you generate new ideas.
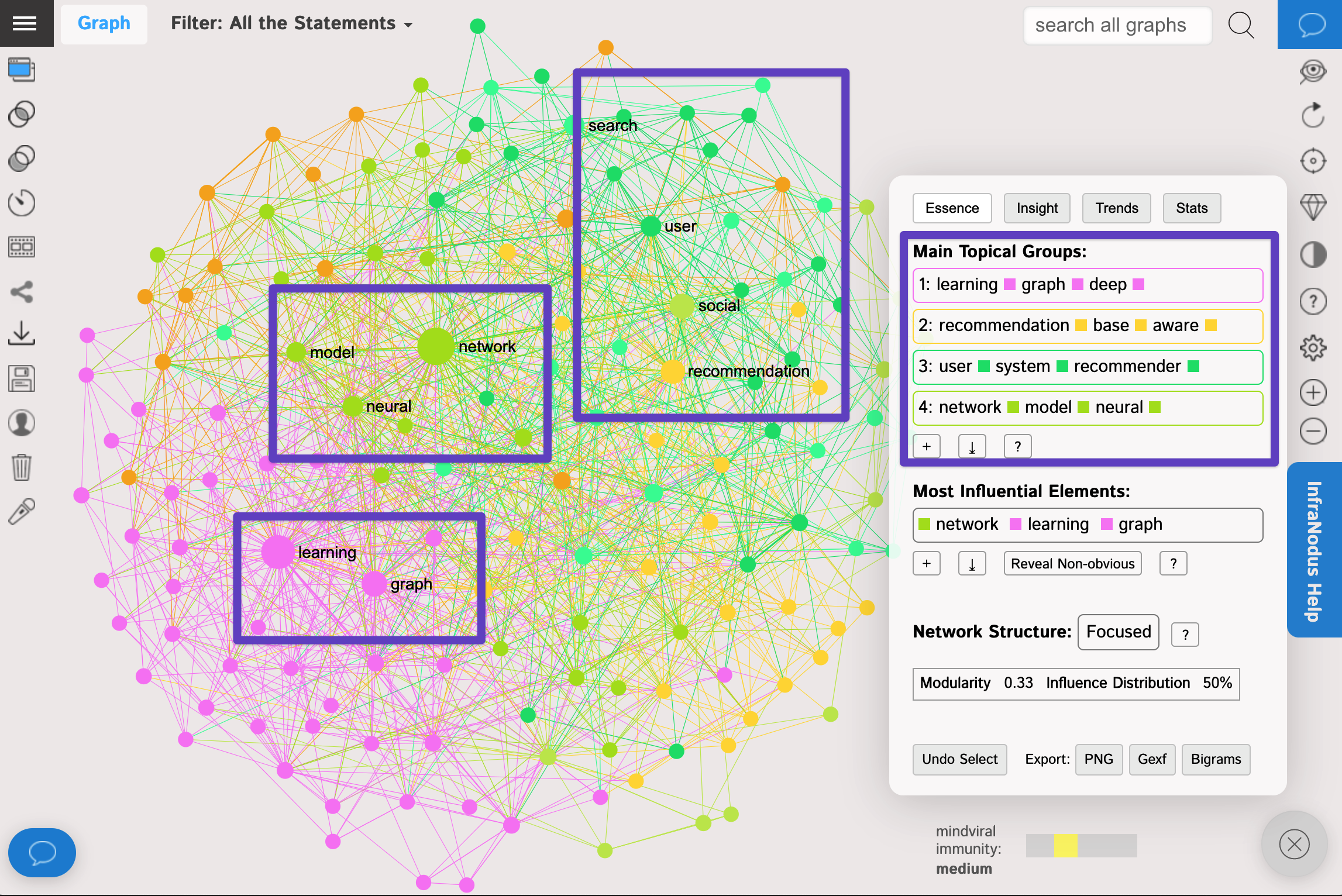
In this particular example we can see that all the papers are mainly about neural networks and machine learning algorithms as well as recommendation systems. Seems to be a hot topic in the web these days.
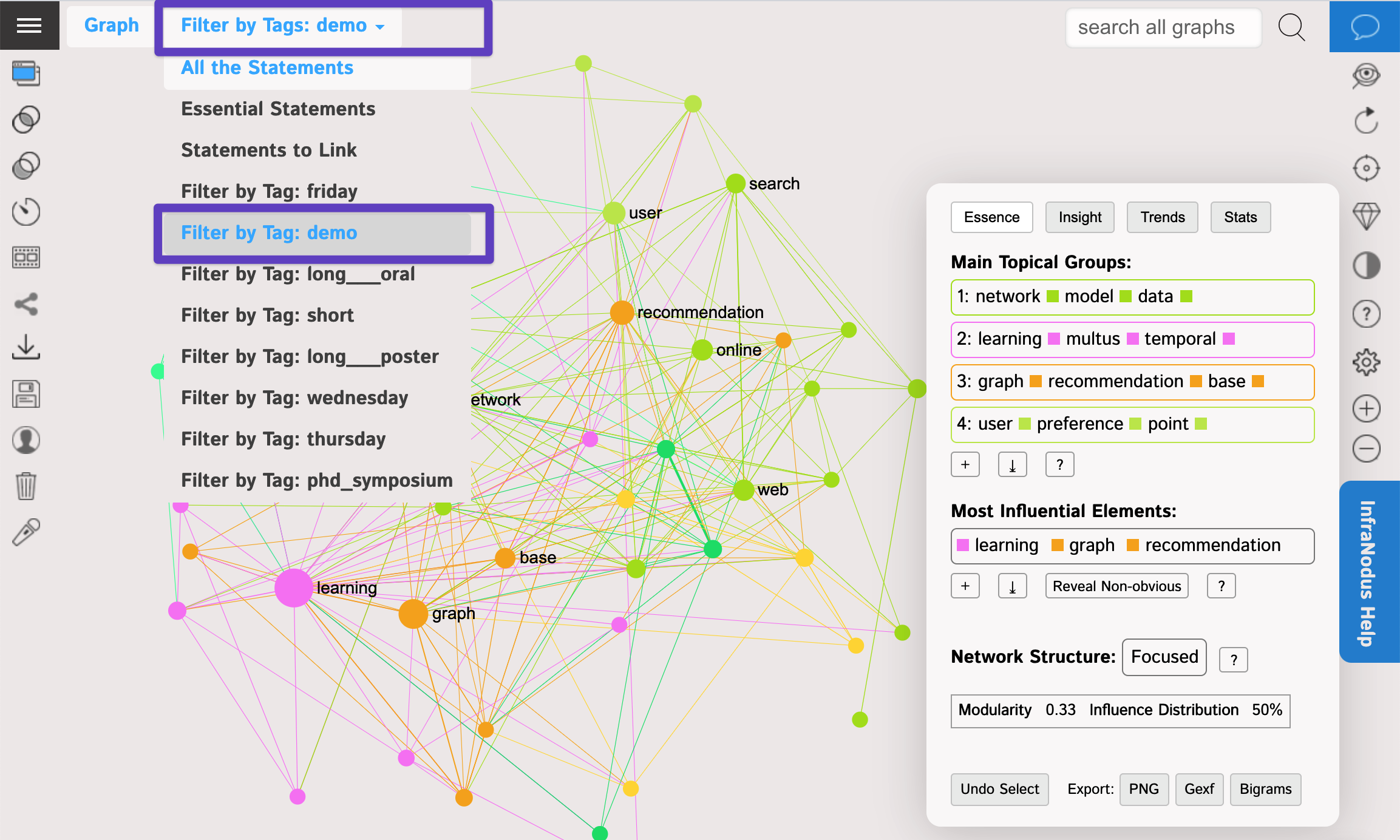
7. If you would like to see the Categories / Filters you added when importing your spreadsheet file, click on the Filter tab at the top menu, so you can see the graph of only the rows in your original CSV file that had "Demo" in their Type column:
Comments
0 comments
Please sign in to leave a comment.