
Problems with Japanese

I've started using the InfraNodus obsidian plugin, but there are various problems and it's not usable.
The biggest problem is that it doesn't support multiple languages, even though it uses AI.
Specifically
(1) It doesn't read [[Wikilink]]s, as shown in the image.
(2) When you specify concepts in Single Page Prosessing, it can't analyze Japanese concepts, and only extracts single kanji characters or kana phrases.
(3) Even with AI-based summarization, the output is in English, and you have to add a prompt to translate it into Japanese one by one.
Basically, this is because InfraNodus's analysis does not support multiple languages. If the current AI were incorporated into InfraNodus itself, then if it were possible to specify languages such as “Japanese” in the settings, then the problem in (3) would be solved, and if the AI were to analyze it, then the problem in (2), which is that the concept is not supported in Japanese, would be solved. I think that (1) is also not supported in Japanese. In my case, it's Japanese, but I suspect that the problem is occurring in other languages as well. Please fix this, as it's a great plugin and app that can analyze graphs.
Thanks.
Image about (3) Image about (2)
Image about (2) Image about (1)
Image about (1)
-
Official comment

Hi! Thank you for your feedback.
I wanted to let you know that it has been taken into account and now should be working with Japanese the way you expected.
Could you please check it and let us know what you think?
-
I’ve checked the latest version, and I can confirm that Japanese text is now being tokenized correctly. It’s successfully extracting meaningful concepts like compound words instead of single characters, which is a huge improvement.
I’m really looking forward to seeing these improvements reflected in the Obsidian plugin as well. Being able to use this level of Japanese analysis directly within my local PKM workflow would be incredibly valuable for my research.
Thanks for your great work!0 -
I’ve tested the improved Japanese support, and I can confirm that the tokenization engine itself is working correctly! It is now successfully extracting important compound words like “構造” (Structure) and “観客” (Audience), which is a great improvement.
However, I noticed that there are still many single-character nodes appearing in the graph, such as “十” (ten), “分” (minute/part), “一” (one), and “見” (see).
In Japanese morphological analysis, this is not exactly a bug, but rather an issue of stopword optimization. These characters are technically words, but they act as “noise” in a concept graph unless they are part of a compound word.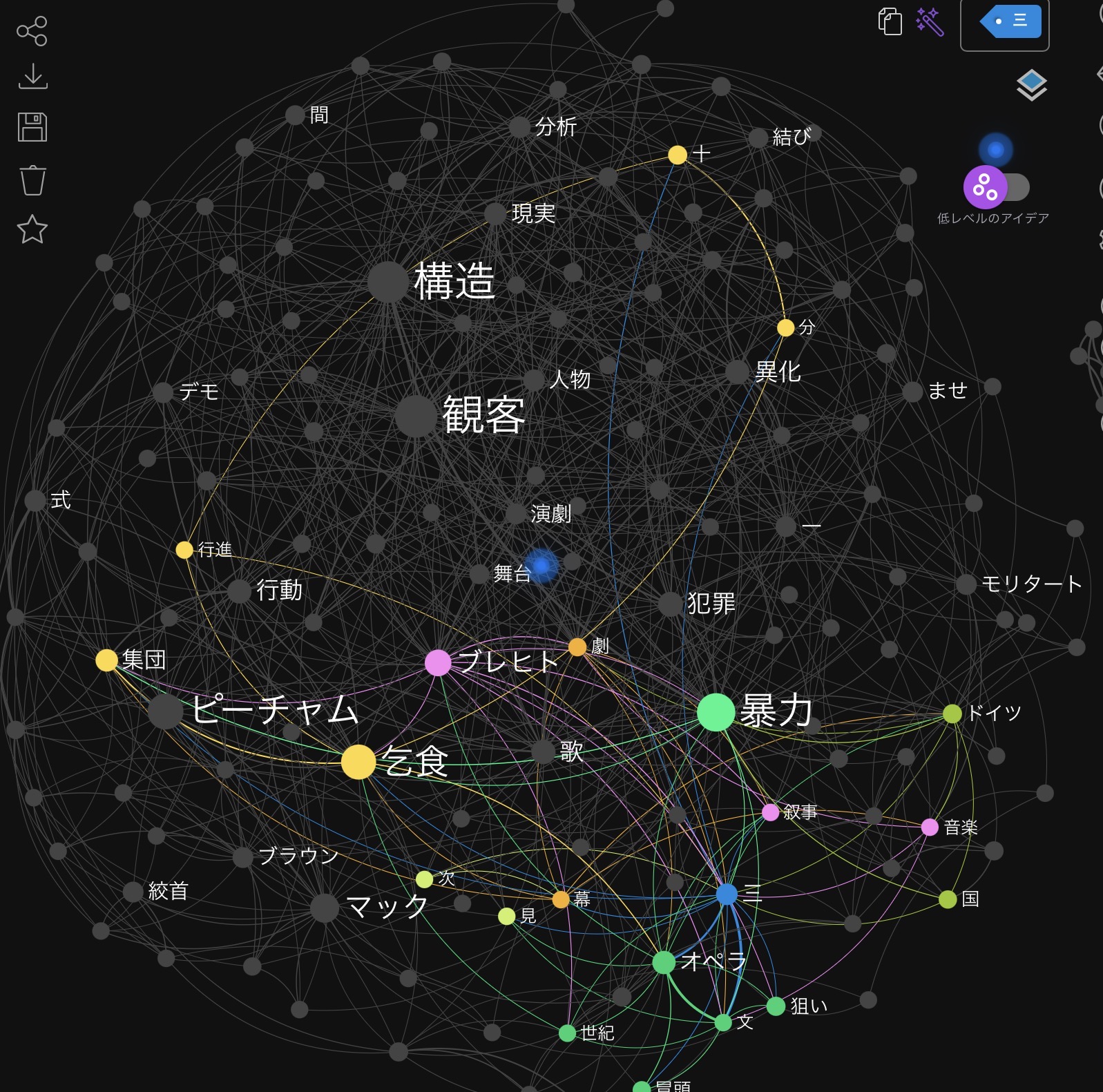
To make the default Japanese setting more usable out-of-the-box, I recommend adding single-character numerals and common abstract parts of speech to the default exclusion list.
I will customize my own list for now, but I thought this feedback might help improve the default Japanese experience for future updates.0
Please sign in to leave a comment.
Comments
3 comments